
DeepSeek新数学模型刷爆记录!7B小模型自主发现671B模型不会的新技能
量子位 2025-05-02 16:18:22
DeepSeek数学模型强化学习发现新技能
DeepSeek放大招!新模型专注数学定理证明,大幅刷新多项高难基准测试。
在普特南测试上, 新模型 DeepSeek-Prover-V2 直接把记录刷新到 49道 。
目前的 第一名 在657道题中只做出 10道 题,为Kimi与 AIME2024冠军团队Numina 合作成果 Kimina-Prover 。
而未针对定理证明优化的 DeepSeek-R1只做出 1道 。
让还没发布的R2更令人期待了。
除测评结果之外,论文中特别报告了 “通过强化学习发现新技能” 现象。
正如R1带来了“啊哈时刻”,Prover-V2也有令人意想不到的能力。

具体来说,在普特南测试中,参数量较小的DeepSeek-Prover-V2-7B用非CoT生成模式成功解决了13个671B模型未能解决的问题。
团队仔细检查该模型的输出后发现,其推理方法存在一个独特模式:7B模型处理涉及有限基数的问题时,经常使用 Cardinal.toNat 和 Cardinal.natCast_inj ,而671B模型生成的输出中明显没有这些内容。
要注意,7B模型是在DeepSeek-Prover-V1.5-Base模型基础上,先使用671B模型在强化学习阶段收集的数据微调,再执行强化学习得来的。
也就是说,7B模型学会了671B模型没有学会的新技能。

DeepSeek数学模型系列
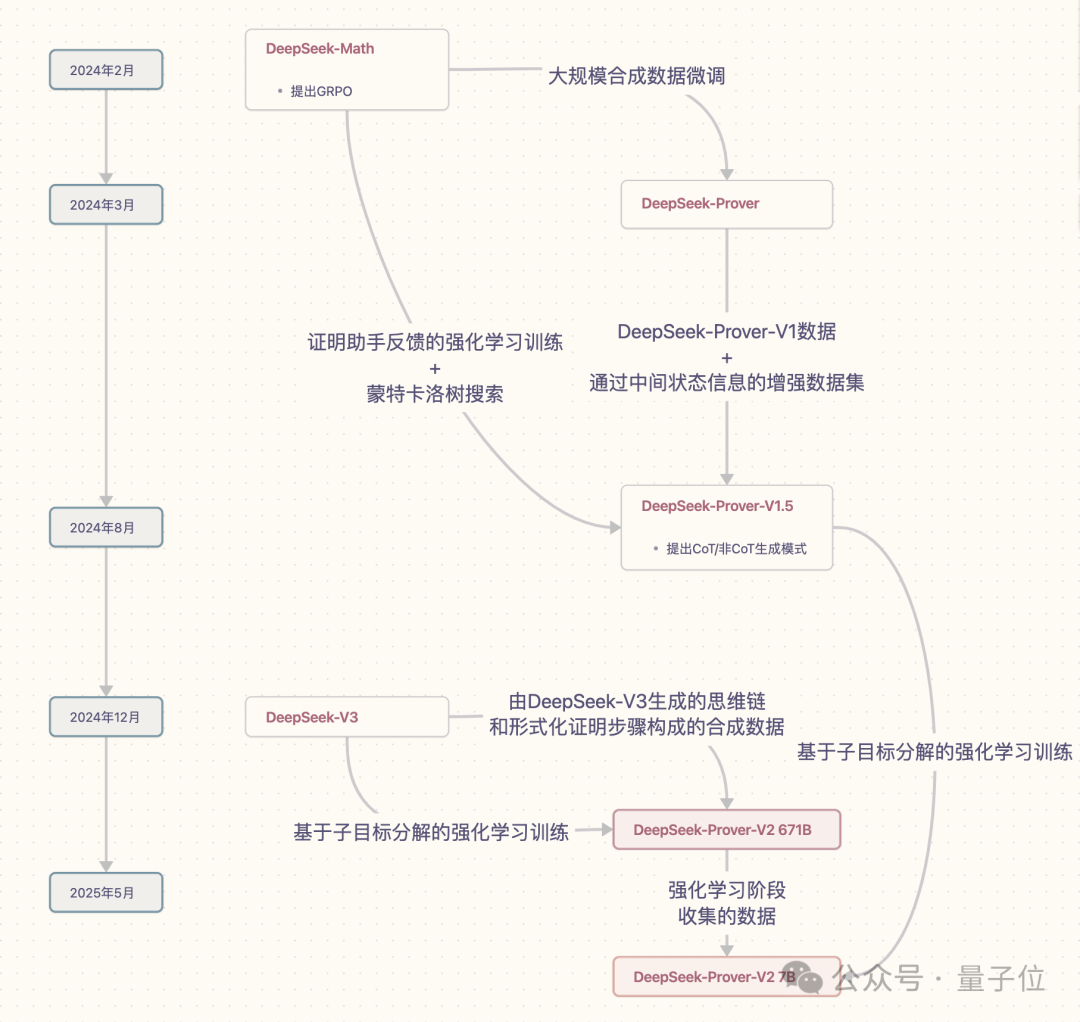
DeepSeek数学定理证明DeepSeek-Prover系列模型已推出3款:
2024年3月的 DeepSeek-Prover (后简称为Prover-V1) 2024年8月的 DeepSeek-Prover-V1.5 (后简称为Prover-V1.5) 2025年5月的 DeepSeek-Prover-V2 (后简称为Prover-V2)Prover-V1 主要探索了 通过大规模合成数据集微调DeepSeek-Math-7B ,来推进定理证明。
Prover-V1.5 在此基础上增加了 证明助手反馈的强化学习 (RLPAF)和 蒙特卡洛树搜索 方法。
Prover-V2 进一步提出 “子目标分解的强化学习” ,并且基础模型从DeepSeek-Math-7B升级到DeepSeek-V3。
整合DeepSeek-V3的高上下文窗口和强大的自然语言推理能力,把形式化和非形式化数学证明统一到一个模型中。
Prover-V2还继承了Prover-V1.5提出的CoT和非CoT生成两种模式。
DeepSeek数学模型作者阵容
Prover-V2的作者共18人,共同一作 Z.Z. Ren, 邵智宏、辛华剑 都是参与过V3、R1以及Prover系列前作的主力成员。
作者名单中出现了几位未参与前两代版本 (Prover-V1、Prover-V1.5) 的研究者。
比如 Shirong Ma ,清华本硕。公开资料显示,他于去年毕业后即加入DeepSeek,现为DeepSeek研究员,此前参与了从DeepSeek LLM v1到R1以及DeepSeek-Coder等工作。

还有 Zhe Fu、Yuxuan Liu 。
虽然他们都没出现在Prover-V1、Prover-V1.5的作者名单中,但均为DeepSeek资深成员。
最后还有一位新面孔 Hongxuan Tang ,暂未了解到具体信息。
(选自《量子位》微信公众号,《DeepSeek新数学模型刷爆记录!7B小模型自主发现671B模型不会的新技能》,编发有删减)
责任编辑:i泺源 汤代禄